ユーザーは、分析機能が製品内の他のすべての機能と同様に動作することを期待しています。つまり、高速で、コンテキストに依存し、業界を問わず製品ワークフロー内で利用できることです。従来のダッシュボードには、セットアップと専門知識が必要です。ほとんどのAIツールは、深さをスピードと交換し、一時的な回答を返します。
AI生成ダッシュボードは、このギャップを埋めます。これは、質問を、既存の分析スタック内で機能する、永続的で再利用可能なビューに変換します。この記事では、プロダクションチームがこれらをどのように構築するか、そしてアーキテクチャ上の選択がAIダッシュボードがスケールするか、それとも破綻するかを決定する理由を説明します。
AI生成ダッシュボードとは何ですか?
ほとんどのチームはこの用語を聞くと、チャートを返すチャットウィンドウを想像します。しかし、その視点は本質を捉えていません。真の変化はインターフェースではありません。システムが生成する「成果物」です。
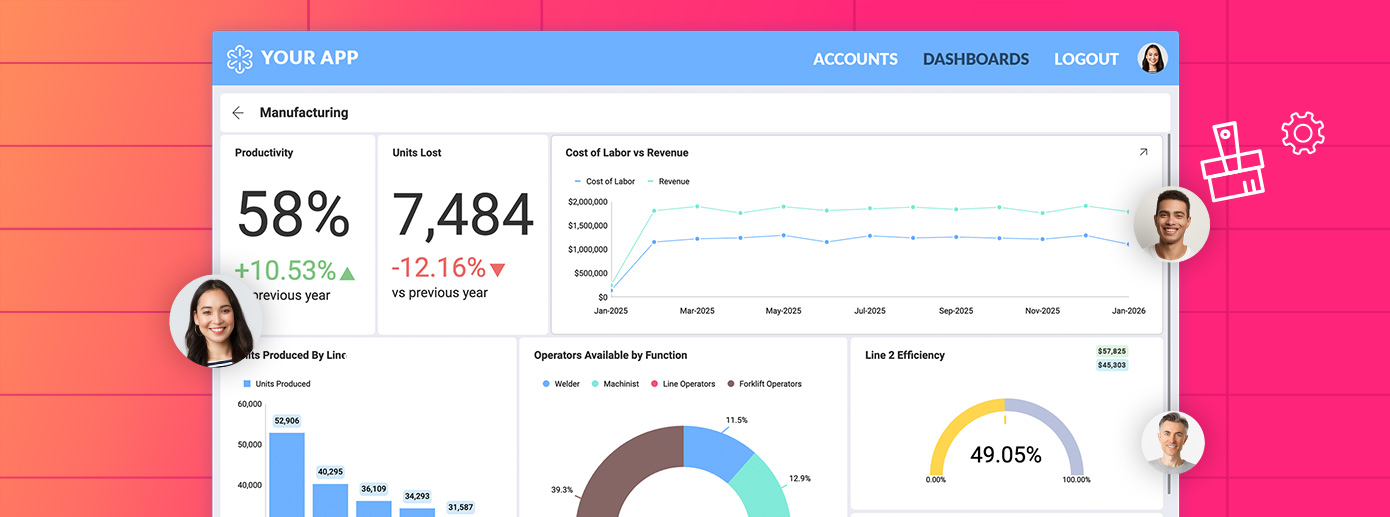
AI生成ダッシュボードとは、ユーザー定義のクエリから作成または修正される永続的なダッシュボードです。システムは意図を解釈し、データを選択し、ビジュアライゼーションを選び、レイアウトのメタデータを構築します。その出力は、製品内の他の組み込みダッシュボードと同じように動作します。永続的であり、フィルターやドリルダウンアクションをサポートし、既存の権限とデータモデルを通じて実行されます。

AI生成ダッシュボードと会話型出力とを分けるのは、作成後にどのように保持されるかという点です。
- 初期クエリを超えて永続し、保存および共有できます。
- 標準的なダッシュボードと同様に、フィルター、ドリルダウンアクション、ビジュアル編集をサポートします。
- 手動で構築されたダッシュボードと同じ権限とデータモデルを通じて実行されます。
この定義は重要です。なぜなら、多くのツールは応答生成で止まってしまうからです。この違いを理解することが、今日のほとんどのAIダッシュボードがどのように構築されているか、そしてなぜそのアプローチがしばしば破綻するのかという背景を築きます。
AI生成ダッシュボードが現在一般的に構築される方法
ほとんどのAIダッシュボードの実装は、同じパターンに従います。
- ユーザーが自然言語で質問を入力します。
- モデルがプロンプトを解釈し、クエリを生成します。
- システムがそのクエリをデータベースに対して実行します。
- 結果がチャートまたは短い応答としてレンダリングされます。
このアプローチは、会話型分析 や 拡張分析 のようなラベルの下で、デモのスピードを最適化しているように見えることがよくあります。直感的で、分析スタックを変更することなく迅速に価値を示します。
問題点は、出力がその瞬間だけ存在することです。ユーザーはそれを洗練したり、保存したり、後で戻ったりすることができません。これらの制限は、チームがデモの域を超えて日常的な使用に移行しようとするときに明らかになります。
ほとんどのAI生成ダッシュボードがエンタープライズおよびSaaS製品で破綻する理由
AIダッシュボードは、高速な回答を最適化しているため、デモでは印象的です。しかし、製品が実際のセキュリティ、スケール、ガバナンスの制約に直面すると、同じ設計は破綻します。
ほとんどの失敗はデータ漏洩から始まります。多くのAI生成ダッシュボードは、言語モデルによって作成されたアドホッククエリに依存しています。これは、組み込み分析におけるセキュリティ や、セキュリティと分析 に関する広範な懸念で概説されているように、プロダクションシステムで期待されるセキュリティプラクティスをバイパスします。権限と監査可能性が重要になると、信頼は急速に失われます。
マルチテナント SaaS製品は、さらに厳しい制限に直面します。単一のプロンプトは、テナントの境界、ロールベースのアクセス、データ分離を尊重しなければなりません。チャット駆動型のダッシュボードは、組み込み分析におけるマルチテナンシーデータ の分析で説明されているように、ここで苦労します。なぜなら、リクエストごとに漏洩の新たな表面となるからです。

ユーザーエクスペリエンスの問題が密接に続きます。外部ツールやiFrameでレンダリングされたダッシュボードは、ユーザーをワークフローから引き離します。コンテキストの切り替えは採用を減らし、継続性を妨げます。これは、組み込み分析とiFrameの比較 で強調されている一般的な問題です。ユーザーは分析を製品の一部として見なくなります。
これらの失敗は共通の根本原因を共有しています。AIは、分析ライフサイクル内ではなく、外部で動作します。このギャップが、チームがアプローチを再考し、AIが既存のコントロール内で機能するアーキテクチャを探す理由を説明しています。
AI生成ダッシュボードを保護する方法
多くのチームは、AIが有用であるためにはデータへの直接アクセスが必要だと信じています。その信念がリスクを生み出し、採用を遅らせます。安全なAI生成ダッシュボードは、異なるパスをたどります。それは、コントロールを製品内部に維持するパスです。
最も安全なアプローチは、AIをデータレイヤーから完全に排除することです。データベースをクエリする代わりに、AIは分析メタデータと連携します。この区別は微妙ですが、AIがプロダクションシステムで動作できるかどうかを定義します。
AIはSQLを生成すべきではない
一部のAIツールは、動的にSQLを生成します。その設計は、データベースを予測不可能な動作と権限のギャップにさらします。十分にテストされたモデルでさえ、ルールをバイパスするクエリを生成する可能性があります。
より安全なパターン:AIは、分析SDKモデルを使用してダッシュボード定義を生成します。これらの定義は、実行ではなく、構造と意図を記述します。すべてのダッシュボードは、手動で構築されたものと同じ実行パスをたどります。
ダッシュボードは既存のセキュリティコンテキストを通じて実行される必要がある
製品はすでにアクセスルールを強制しています。AIのためにそれらのルールを置き換えることは、盲点を作り出します。
安全なAIダッシュボードは、承認されたデータソースに対してのみ実行されます。ユーザーコンテキストは、テナント分離やロールベースのアクセスを含め、自動的に適用されます。AIは、ユーザーがすでに持っている以上の可視性を拡大することはできません。
このアプローチは、AI分析 がエンタープライズ製品でどのように振る舞うべきかということを反映しています。インテリジェンスは既存のシステムに適応します。
AIが解釈できるものを制御する
すべてのデータがAIに公開されるべきではありません。チームは、AIが参照できるものを制限する能力を必要とします。テーブル、ビュー、またはフィールドをホワイトリスト化することは、有用性を減らすことなくスコープを制限します。
ドメイン言語も重要です。ビジネス用語は、承認されたフィールドや定義にマッピングできます。これにより、探索を制限しつつ、精度が向上します。ガバナンスは、後付けではなく、設定の一部になります。
このモデルは、エンタープライズのセキュリティ の期待に合致しています。AIは役立ち続けますが、決して自律的ではありません。
ユーザークエリからAI生成ダッシュボードへ、ステップバイステップ
ユーザーはめったにチャートを要求しません。彼らは、下さなければならない決定を反映した質問をします。課題は、その意図を製品が実行し、再利用できるものに翻訳することです。
効果的なAI生成ダッシュボードのワークフローは、自然言語を指示ではなく出発点として扱います。システムはユーザーの意図を解釈し、構造を構築し、残りの処理は既存の分析ランタイムに依存します。
ステップ1:ユーザーの意図の解釈
最初のタスクは、ユーザーが何をしようとしているのかを理解することです。単一の入力は、コンテキストに応じて非常に異なるアクションを示す可能性があります。
一般的な意図のカテゴリには以下が含まれます。
- 新しいダッシュボードの作成
- 既存のダッシュボードの編集
- ビジュアライゼーションの分析
- ダッシュボードの要約
例えば、「売上と注文のダッシュボードを作成」は作成を示します。「総売上ウィジェットを追加」は変更を示します。正しい意図分類が重要です。なぜなら、各パスが異なるワークフローをトリガーするからです。このステップがなければ、システムは推測し、ユーザーはすぐに信頼を失います。
ステップ2:ダッシュボードメタデータの生成
意図が明確になったら、システムはクエリレベルではなく、メタデータレベルでダッシュボード定義を構築します。
AIが定義するもの:
- フィールドとメジャー
- 集計
- ビジュアライゼーションタイプ
- レイアウトルール
例えば、「国別売上ツリーマップを追加」は、新しいウィジェット定義の結果となります。メタデータは、そのウィジェットがどのように見え、どのように動作すべきかを記述します。まだデータは実行されません。この分離により、AI生成ダッシュボードが予測可能で監査可能であり続けることができます。
ステップ3:分析ランタイムを通じた実行
メタデータが準備された後、実行が始まります。ダッシュボードは、製品が現在使用している既存の組み込み分析パイプラインを通じてレンダリングされます。
この段階で、セキュリティとガバナンスが引き継ぎます。クエリは承認されたデータソースに対してのみ実行されます。フィルター、行レベルのルール、ユーザーコンテキストが自動的に適用されます。AIは、自身がクエリを実行することはないため、いかなるチェックもバイパスしません。
出力は、システム内の他のダッシュボードと同じように動作します。ユーザーは期待通りにドリルダウンしたり、フィルターをかけたり、対話したりできます。
ステップ4:ダッシュボードの永続化と再利用
最終ステップは、出力を資産に変換することです。ダッシュボードは保存され、共有され、後で再訪できます。
これは実際のワークフローにおいて重要です。ユーザーは分析中にダッシュボードを作成し、その後、経営会議の前に「このダッシュボードを要約」と尋ねるかもしれません。同じダッシュボードが、探索とコミュニケーションの両方をサポートします。時間の経過とともに、AI生成ダッシュボードは、使い捨ての回答ではなく、製品の分析レイヤーの一部になります。
AI支援によるダッシュボードの編集と進化
ダッシュボードはめったに最終的な状態にとどまりません。チームは、質問が変わるにつれて、メトリクスを調整し、コンテキストを追加し、ビューを再構築します。ほとんどのツールは、これらの変更を再構築として扱い、摩擦を加え、採用を遅らせます。
AIは、置き換えではなく反復をサポートすることで、そのパターンを変えます。ユーザーは、ゼロから始めるのではなく、既存のものを調整します。
自然言語による既存ダッシュボードの編集
ダッシュボードが存在すると、ほとんどの変更は漸進的です。ユーザーはエディターを開いたり、レイアウトルールを理解したりしたくありません。彼らは、必要な変更を説明したいだけです。
一般的な編集リクエストには以下が含まれます。
- 「総売上ウィジェットを追加」
- 「国別売上ツリーマップを追加」
- 「地域によるグローバルフィルターを追加」
各リクエストは、既存のダッシュボードメタデータを更新します。ウィジェットはコンテキスト内で表示され、レイアウトは自動的に調整され、権限は変更されません。このアプローチは、ダッシュボードを安定させつつ、迅速な反復を可能にします。
作成ではなく分析のためのAIの使用
作成は注目を集めますが、分析が価値を提供します。チームは、新しいチャートよりも説明を必要とすることがよくあります。
AIは、単一のビジュアライゼーション全体、またはダッシュボード全体を分析できます。ユーザーは、経営レビューの前に「このダッシュボードを要約」と尋ねるかもしれません。システムは既存のウィジェットを検査し、現在のデータに基づいて明確なナラティブを生成します。
これにより、手戻りが回避されます。ダッシュボード自体が、説明と議論のソースになります。
ダッシュボードから意思決定ナラティブへ
ダッシュボードは、製品を超えた意思決定をサポートすることがよくあります。エグゼクティブはインターフェースではなく、要約を必要とします。
AIは、そのギャップを埋めるのに役立ちます。オペレーション向けに作成されたダッシュボードは、管理職向けに短いナラティブを生成できます。その要約は、製品内、またはメールやレポートに移動することができます。
チームは一度構築し、ニーズの変化に応じて出力を適応させます。これにより、重複が減り、分析が実際の決定と整合性を保ちます。
ドメイン固有言語とビジネスコンテキストがAI生成ダッシュボードを改善する方法
モデルはセキュリティルールに従っても、間違った出力を返すことがあります。これは、ユーザーの言語がデータの言語と一致しない場合に発生します。精度は、ビジネス用語をデータフィールドにどれだけうまくマッピングできるかに依存します。
一般的な言語がAIダッシュボードを破綻させる理由
ユーザーは、スキーマラベルではなく、ビジネス用語で話します。彼らは「収益」、「注文」、または「アクティブアカウント」を尋ねます。あなたのデータベースは、異なる名前と定義を保存しているかもしれません。
このギャップが曖昧さを生み出します。システムは間違ったフィールドやメトリクスを選択する可能性があります。AI生成ダッシュボードは、権限が正しい場合でも、一貫性がないように見えることがあります。これを修正するには、システムに語彙を教える必要があります。
ビジネス用語をデータフィールドにマッピングする
簡単なエイリアスレイヤーと言語を一致させることができます。ビジネスでその用語が何を意味するかを定義し、特定のフィールドにマッピングします。
例えば、あなたのチームは「注文ID」の代わりに「chop chop」と言うかもしれません。そのマッピングがない場合、システムは推測します。マッピングがある場合、システムは予測可能に動作します。
ここに、実装できる実用的なセットアップフローがあります。
- ユーザーがチケットや通話で実際に言うビジネス用語をリストアップします。
- 各用語を、フィールドのグループではなく、単一のフィールドにマッピングします。
- 意味と使用法を明確にする短い説明を追加します。
- マッピングを設定ファイルまたはメタデータサービスに保存します。
- そのテナントまたはワークスペースのAI初期化時にマッピングをロードします。
- ミスをログに記録し、時間とともに語彙を拡張できるようにします。
このアプローチは推測を減らし、再現性を向上させます。また、マッピングが明示的であるため、レビューも容易になります。
ホワイトリスト化によるスコープの制限
語彙はシステムが正しいものを選ぶのを助けます。スコープ制御は、間違ったものを選ぶのを防ぎます。
ホワイトリスト化は、AIが参照できるものを制限します。特定のテーブル、ビュー、または主題領域へのアクセスを制限できます。これにより、偶発的な探索が減り、応答の品質が向上します。AI生成ダッシュボードは、ユーザーとテナント全体で一貫性を保ちます。
AIとベクトル検索による既存ダッシュボードの再利用
AIが分析に参入すると、チームはすぐにパターンに気づきます。すべての質問が何か新しいものを生み出すからです。時間の経過とともに、ダッシュボードは増殖し、回答は分岐し、信頼は低下します。
この問題は、モデルが劣っていることから生じるものではありません。すべての質問を「作成リクエスト」として扱うことから生じます。AI生成ダッシュボードがスケールするのは、再利用がデフォルトになる場合だけです。

毎回新しいダッシュボードを生成することが失敗する理由
すべての質問に対して新しいダッシュボードを作成することは、最初は役立つように感じられます。それは即座のリクエストを解決し、生産的であるように見えます。しかし、時間の経過とともにノイズを生み出します。
複数のダッシュボードが、わずかに異なる方法で同じ質問に回答します。チームはどれが正しいのか分からなくなります。ユーザーは自信を失い、手動チェックに戻ります。解決策は、絶え間ない再生成よりも、既知の信頼できる資産を優先することです。
メタデータによるダッシュボードへの意味の埋め込み
ダッシュボードにはすでに構造が含まれています。タイトル、ウィジェット、フィルター、レイアウトはすべて意図を表現しています。その意図は、メタデータとしてキャプチャされると検索可能になります。
各ダッシュボードは、記述的なコンテキストを保存できます。これには、ダッシュボードが何に答えているか、どの質問をサポートしているか、どのように使用されているかが含まれます。そのメタデータは、ダッシュボード定義と並んで存在し、ダッシュボードが変更されるときに更新されます。AI生成ダッシュボードは、孤立した出力ではなく、発見可能な資産になります。
再構築するのではなく、ダッシュボードを見つける
これが実際にどのように機能するかを説明します。
チームは「注文と売上概要」という既存のダッシュボードを持っています。これには、総注文数、総売上、国別売上が含まれています。このダッシュボードはまた、それが回答する一般的な質問を記述するメタデータも保存しています。
ユーザーが「総注文数は?」と尋ねます。何か新しいものを作成する代わりに、システムはベクトル類似性を使用して既存のダッシュボードを検索します。質問を保存されたダッシュボードメタデータと比較し、信頼度スコアとともに最も近い一致を返します。
信頼度が高い場合、システムは既存のダッシュボード、またはそこからの特定のウィジェットをロードします。ユーザーはすぐに信頼できる結果を得ます。重複は発生しません。AI生成ダッシュボードは、無限のバリアントのための工場ではなく、検証された分析に対するリトリーバルレイヤーのように振る舞うようになります。
RevealをAI生成ダッシュボードプラットフォームとして
多くのチームは、最も難しい決定はモデルの選択だと考えます。実際には、真の課題はアーキテクチャです。AI生成ダッシュボードがスケールするのは、AIが分析レイヤーの外ではなく、内部で動作する場合だけです。

この記事は、プロダクションレベルのAIダッシュボードに何が必要かを示しました。意図が作成を推進し、メタデータが構造を定義し、既存のセキュリティがアクセスを強制し、再利用が肥大化を防ぐことです。これらのピースが繋がるとき、ダッシュボードは耐久性のある製品資産になります。
それがRevealの背後にあるモデルです。
- AI生成ダッシュボードは、完全なブランディングコントロールを備え、製品内部で実行されます。
- AIはメタデータで動作し、既存のセキュリティモデルを維持します。
- ユーザーは、自然言語を通じてダッシュボードの作成、編集、分析、再利用ができます。
- プロダクトチームは、ブランディング、UX、およびデプロイメントのコントロールを保持します。
SaaSチームおよびISVにとって、結果は実用的です。ユーザーはより速く回答に到達し、チームはダッシュボードのメンテナンスを削減し、製品が成長しても分析が一貫性を保ちます。
See The Power of AI Analytics
Revealで組み込み分析の新時代に足を踏み出す