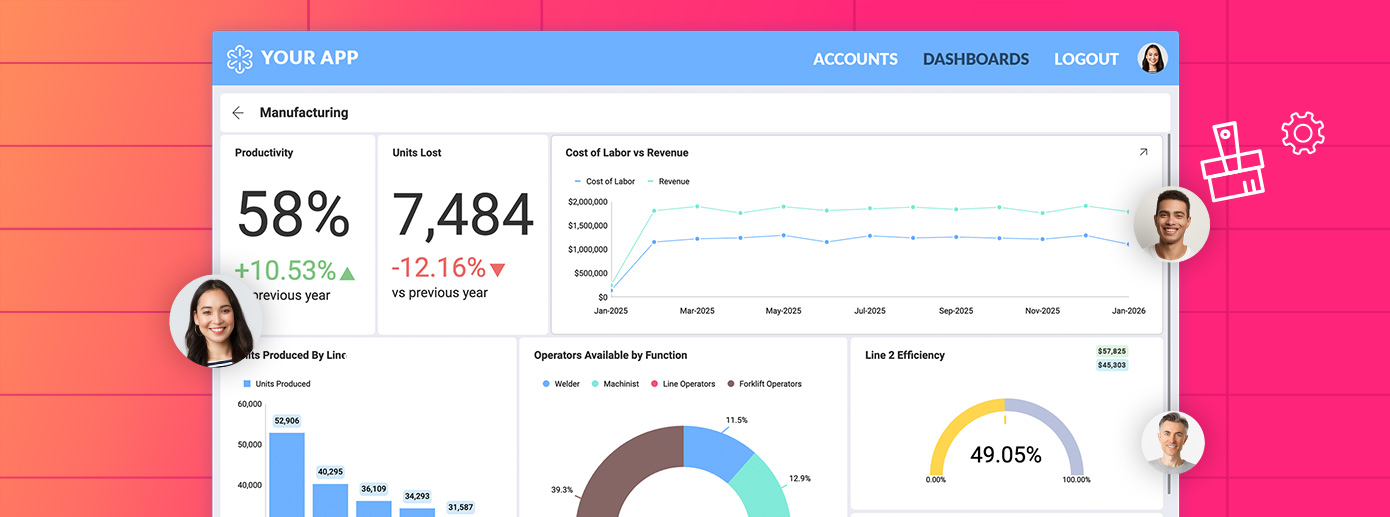
AIは、SaaS製品内の分析レイヤーとのユーザーのインタラクション方法を再構築しました。単に 組み込み分析 を製品に追加するだけでは、採用や継続率の向上にはつながりません。ユーザーは、ChatGPTやGeminiのようなツールで自然な会話形式でデータを探索することを期待するようになりました。
会話型分析 は急速にベンチマークとなりました。これにより、ユーザーはダッシュボードにクエリを実行したり、メトリックを要約したり、関連するコンテキストデータで埋められた完全なダッシュボードを生成したり、トレンドを探索したりできます。簡単な質問で、関連するコンテキストデータで埋められた完全なダッシュボードを生成できます。
これらの期待に応えるために、多くの製品チームは、自然言語によるインタラクションで分析エクスペリエンスをアップグレードするための最速の方法として、大規模言語モデル(LLM)に目を向けます。しかし、LLMを直接統合すると、多くの場合、新しい問題が発生します。トークンコストが急速に増加し、ガバナンスの適用が難しくなり、機密データがアプリケーション環境、さらには顧客のクラウド境界から漏れ出す可能性があります。
小規模言語モデルは、組み込み分析のための代替手段を提供します。大規模モデルをデフォルトで使用するのではなく、チームは現在、SLMとLLMを、パフォーマンス、コスト、および制御のトレードオフとして扱っています。小規模モデルは、多くの場合、運用分析タスクをより効率的に処理し、データと実行を定義された境界内に維持します。
分析を製品に組み込んでいるSaaS企業にとって、適切なAIモデル戦略の選択は、パフォーマンス、コスト、およびユーザーエクスペリエンスに直接影響します。
AI分析には、LLMだけでは不十分な理由
組み込み分析レイヤーにLLMを追加すると、多くの場合、最も迅速な方法でエクスペリエンスをアップグレードできると感じるかもしれません。 AI分析 実装は、分析システムが実際にどのように動作するかを反映していない可能性があります。
「 AIを活用したアナリティクス 」に関する業界の議論は、多くの場合、モデルの機能に焦点を当てています。推論の深さと言語の流暢さが最も注目されています。ただし、分析プラットフォームは、チャットシステムとは非常に異なる条件下で動作します。構造化されたデータに対して繰り返しのクエリを処理し、ほぼリアルタイムで応答する必要があるユーザーインターフェイス内でインサイトを提供します。

チャットボットは、時折プロンプトに答えます。分析レイヤーは、毎日数千の質問に答えます。すべてのダッシュボードのリフレッシュ、メトリックの説明、またはトレンドの要約は、別のモデルリクエストをトリガーします。大規模になると、そのワークロードは、LLMのみのアーキテクチャの限界を急速に明らかにします。
分析ワークロードには、通常、次のものが含まれます。
-
頻繁なダッシュボードのリフレッシュ
-
繰り返しのKPIの説明
-
高いユーザーの同時実行性
-
ほぼ瞬時のUI応答の期待
これらのパターンは、コスト、レイテンシー、およびガバナンスにプレッシャーをかけます。会話に適したモデルは、継続的な分析の需要の下では苦戦する可能性があります。この現実により、パフォーマンス主導のデザインへの移行が促されます。これらの条件下では、SLMとLLMは、レイテンシー、スループット、および安定性が重要な、各モデルが継続的な負荷の下でどのように機能するかを強調します。
大規模言語モデル(LLM)とは?
大規模言語モデルは、大規模なテキストデータセットでトレーニングされたニューラルネットワークを使用して自然言語を処理します。質問を解釈し、応答を生成し、大量の情報を相互に関連付けます。分析環境では、LLMはユーザーの質問を意味のあるデータ探索に変換するのに役立ちます。
その強みは、複雑なリクエストを処理することにあります。ユーザーは、収益が減少した理由や、どの地域が成長を牽引しているかを尋ねることができます。モデルは言語を解釈し、利用可能なデータを使用して説明を生成します。この機能により、LLMは、多くの場合、「 エンタープライズBI)およびエグゼクティブレポートに関連付けられているシステム内の高度な分析インタラクションに役立ちます。
LLMは、次のタスクを実行するときに特に優れたパフォーマンスを発揮します。
-
自然言語の質問を理解する
-
詳細な説明を生成する
-
あいまいなリクエストを解釈する
-
データからナラティブなインサイトを生成する
これらの機能により、LLMはAI駆動のインターフェイスを構築する分析チームにとって魅力的になります。ユーザーは、クエリを作成したり、複雑なダッシュボードを操作したりすることなく、データを探索できます。多くの組織にとって、このモデルタイプは、会話型データインタラクションへの最初の一歩になります。
ただし、モデルの機能が常にアーキテクチャの効率に変換されるとは限りません。分析プラットフォームは、継続的なクエリと構造化されたデータ操作を生成します。推論の深さとシステム効率のバランスは、多くの場合、SLMとLLMによって決まります。特に、大規模な分析環境では、これらのトレードオフは、組み込み分析環境で、分析レイヤーが製品内でどのように機能するかを直接影響します。
小規模言語モデル(SLM)とは?
小規模言語モデルは、LLMと同じトランスフォーマーアーキテクチャを使用しますが、パラメータ数が少なくなります。そのサイズが小さいことで、計算要件が削減され、推論が高速化され、頻繁に繰り返されるクエリを処理する必要がある分析システムにとって魅力的になります。
多くの組織は現在、セキュアな組み込み分析環境内にSLMをデプロイしています。アプリケーションに近いモデルを実行することで、機密データを保護し、厳格なガバナンスルールを適用し、AI処理を既存のセキュリティ境界内に維持できます。これらのプラクティスは、「 組み込み分析セキュリティ 」の原則に沿っています。

SLMは、タスクが構造化されたデータと予測可能な質問を含む場合に、優れたパフォーマンスを発揮します。分析ワークロードでは、多くの場合、ダッシュボードとレポート全体で同じタイプの要求が繰り返されます。これらの場合、より小さいモデルは、より高速に応答し、トークンを少なく消費し、運用コストを低く、より予測可能にすることができます。
SLMの一般的な強みは次のとおりです。
-
低い推論レイテンシー
-
削減されたインフラストラクチャ要件
-
簡単なローカルデプロイ
-
低いトークン消費量
大規模になると、間違ったSLMとLLMのアプローチを選択すると、コストが増加するだけでなく、機密データが公開され、レイテンシーが増加し、インフラストラクチャに負担がかかる可能性があります。
組み込み分析がAIアーキテクチャを変える理由
組み込み分析は、製品のネイティブな一部として動作する必要があります。ユーザーは、ワークフローと意思決定を管理するのと同じインターフェイス内でダッシュボードと対話します。この統合により、分析レイヤーには厳格なアーキテクチャ要件が課されます。スタンドアロンのAIツール用に設計されたシステムは、これらの期待を満たせないことがよくあります。
多くのSaaS製品は、SaaS企業が分析をアプリケーション内に直接提供できるように、組み込み分析に依存しています。SaaSプラットフォームが分析を製品に組み込む場合、モデルの動作は、パフォーマンス、コスト、およびユーザーエクスペリエンスに直接影響します。分析エクスペリエンスは、製品インターフェイスと一致し、同じアクセス許可モデルに従い、パフォーマンスを低下させることなく、テナントとユーザー間で拡張する必要があります。これらの制約は、AIモデルが分析レイヤー内でどのように動作するかを決定します。
最新の組み込み分析システムでは、通常、次のものが必要です。
-
」を通じて、ネイティブな製品統合と一貫したブランディング
-
厳格なロールベースのアクセス許可とテナントの分離
-
ダッシュボードとクエリに対する低レイテンシー応答 スケーラブルな分析
「 AIトークンのコスト 」は、大規模になると、もう1つのアーキテクチャ要素になります。各ダッシュボードのインタラクションは、モデルリクエストをトリガーする可能性があります。数千人のユーザーにわたると、これらのリクエストは急速に増加します。
これらの現実が、AIを活用した分析システムの全体的な設計を形作ります。製品に組み込まれた分析内では、SLMとLLMは、AIがユーザーエクスペリエンス、セキュリティモデル、およびパフォーマンスの期待にどれだけシームレスに適合するかを決定します。
分析におけるSLMとLLM:実用的な比較
モデル間の選択は、多くの場合、モデルのインテリジェンスだけでなく、システムの動作によって異なります。分析プラットフォームは、構造化されたクエリを高い頻度で処理します。結果をすばやく返し、インフラストラクチャコストを予測可能に保つ必要があります。パフォーマンス、コスト、および応答性をリアルタイム分析の要件に合わせて調整することで、SLMとLLMの選択が、意図したシステム動作によって推進されるようになります。
.slmllm-table-header-controls { display: flex; justify-content: flex-end; align-items: center; margin-bottom: 10px; position: relative; } .slmllm-expand-icon { background: #fff; color: white; border: none; border-radius: 6px; width: 40px; height: 40px; cursor: pointer; display: flex; align-items: center; justify-content: center; transition: all 0.3s ease; backdrop-filter: blur(4px); opacity: 1; visibility: visible; transform: translateY(0); position: relative; z-index: 10; } .slmllm-expand-icon:hover { background: #fff; transform: scale(1.1); } .slmllm-expand-icon img { transition: transform 0.2s ease; } .slmllm-expand-icon:hover img { transform: scale(1.1); } .slmllm-table-responsive { overflow-x: auto !important; -webkit-overflow-scrolling: touch; max-width: 100vw; position: relative; border: none; border-radius: 0.375rem; box-shadow: inset -5px 0 11px 1px #00000014; transition: all 0.5s ease; } .slmllm-table-expanded { position: fixed !important; top: 0; left: 0; width: 100vw !important; height: 100vh !important; z-index: 999999; background: rgba(255, 255, 255, 0.95); margin: 0 !important; border-radius: 0 !important; box-shadow: none !important; overflow: auto !important; padding: 40px 20px 20px 20px; backdrop-filter: blur(10px); -webkit-backdrop-filter: blur(10px); display: flex; align-items: center; justify-content: center; } .slmllm-table-expanded .slmllm-table-responsive { max-width: 95vw !important; max-height: 85vh !important; overflow: auto !important; border-radius: 8px !important; box-shadow: 0 10px 30px rgba(0, 0, 0, 0.3) !important; background: white !important; z-index: 1; } .slmllm-table-expanded .slmllm-comparison-table { min-width: auto !important; width: 100% !important; margin: 0 !important; position: relative !important; top: auto !important; left: auto !important; transform: none !important; max-height: none !important; } .slmllm-table-expanded .slmllm-comparison-table th, .slmllm-table-expanded .slmllm-comparison-table td { white-space: normal !important; word-wrap: break-word; max-width: none !important; padding: 15px 10px !important; font-size: 14px; } .slmllm-table-expanded .slmllm-table-header-controls { display: none !important; } .slmllm-close-expanded { position: fixed; top: 20px; right: 20px; z-index: 1000000; background: #dc3545; color: white; border: none; border-radius: 50%; width: 50px; height: 50px; font-size: 20px; cursor: pointer; box-shadow: 0 4px 8px rgba(0, 0, 0, 0.2); transition: all 0.3s ease; } .slmllm-close-expanded:hover { background: #c82333; transform: scale(1.1); } .slmllm-comparison-table { min-width: 700px !important; margin-bottom: 0; position: relative; } .slmllm-comparison-table thead{ border-bottom: 0; } .slmllm-comparison-table th, .slmllm-comparison-table td { padding: 12px 8px !important; min-width: 50px; border: none !important; text-overflow: ellipsis; overflow: hidden; } .slmllm-comparison-table th { background-color: #f8f9fa; font-weight: 600; position: sticky; top: 0; z-index: 10; } .slmllm-comparison-table tr th { background: #666; color: #fff; } .slmllm-comparison-table tr td { border: none !important; z-index: 1; position: relative; } .slmllm-comparison-table td:first-child, .slmllm-comparison-table th:first-child { position: sticky !important; left: 0; z-index: 5; min-width: 100px; font-weight: 600; border: none !important; overflow: visible; vertical-align: middle; } .slmllm-comparison-table td:first-child::after, .slmllm-comparison-table th:first-child::after { content: ””; position: absolute; top: 0; right: 0; bottom: 0; width: 10px; pointer-events: none; border-right: 1px solid #ccc; box-shadow: 10px 0 10px 0 #00000014; } .slmllm-comparison-table tbody tr:nth-of-type(odd) td:first-child { background-color: #fff !important; } .slmllm-comparison-table tbody tr:nth-of-type(even) td:first-child { background-color: #f5f6fb !important; } .slmllm-comparison-table tbody tr:nth-of-type(even) td { background-color: #f5f6fb; } .slmllm-comparison-table tbody tr:nth-of-type(odd) td { background-color: #fff; } .slmllm-comparison-table th:first-child { background-color: #ec417a !important; z-index: 15; color: #fff; width: 190px; } .slmllm-table-responsive::after { content: ”<-> Swipe to see more <->”; display: block; text-align: center; font-size: 12px; color: #6c757d; padding: 8px; background-color: #f8f9fa; border-top: 1px solid #dee2e6; } .slmllm-table-expanded::after { display: none !important; } @media (min-width: 1200px) { .slmllm-table-responsive::after { display: none; } } @media (max-width: 768px) { .slmllm-expand-icon { width: 35px; height: 35px; } .slmllm-table-expanded { padding: 10px; } .slmllm-table-expanded .slmllm-comparison-table th, .slmllm-table-expanded .slmllm-comparison-table td { font-size: 12px; padding: 8px 5px !important; } }
| 要素 | SLM | LLM |
|---|---|---|
| コスト | モデルサイズが小さいため、運用コストを削減できます | トークンの使用量が増加すると、運用コストが増加します |
| レイテンシー | ダッシュボードやUIの操作に適した、より高速な応答を実現します | モデルサイズによって、推論速度が遅くなる場合があります |
| デプロイ | ローカルまたはプライベートインフラストラクチャ内で実行できます | 通常はクラウドAPIを通じてアクセスされます |
| – 分析自体は、企業が詐欺のリスクを軽減し、データをより適切に保護するのに役立ちます。このようなツールは、パターンを特定して詐欺行為を検出し、防止できるため、企業は安心して業務を行うことができます。たとえば、保険業界があります。 | データはアプリケーション環境内に保持できます | データは外部のモデルサービスに送信されることがよくあります |
| 推論能力 | 構造化されたクエリや反復的なタスクに効果的です | 複雑な推論において優れたパフォーマンスを発揮します |
| スケーラビリティ | 頻繁な分析クエリを効率的に処理します | 高負荷での使用時に、スケーリングコストが増加します |
この比較は、デプロイメントのコンテキストがモデルの選択にどのように影響するかを明確に示しています。分析ワークロードには、反復的なクエリ、構造化されたデータアクセス、および継続的なユーザーインタラクションが含まれます。これらの条件下では、より小さなモデルは、運用タスクを効率的に処理し、レイテンシーとトークンの使用量を制御しながら、優れたパフォーマンスを発揮することがよくあります。
大規模言語モデルは、より高度な推論タスクにおいて依然として価値があります。複雑な質問を解釈したり、より長い分析的な説明を生成したりできます。
各モデルは、分析ワークフローの異なるレイヤーをサポートします。基本的に、SLMとLLMは、システムがこれらのレイヤー間で速度、効率、および推論をどのように分散させるかを示しています。
埋め込み型分析プラットフォームでは、この分散は、システムパフォーマンス、インフラストラクチャコスト、ユーザーエクスペリエンス、およびスケーラビリティに直接影響します。モデルの動作は、ダッシュボードがどれだけ迅速に応答するか、コストがどれだけ予測可能にスケールするか、および分析レイヤーが製品エクスペリエンスにどれだけうまく統合されるかを決定します。
SLMとLLM:どちらを使用すべきか?
ダッシュボード SLMとLLM の選択は、分析レイヤーが速度、スケーラビリティ、および推論の深さをどのようにバランスさせるかによって異なります。高頻度のダッシュボードインタラクションには、高速で効率的な応答が必要です。より複雑な分析的な質問には、より広範なコンテキストとより深い解釈が必要です。各タイプのワークロードは、モデルがシステム内でどのように動作するかを決定します。
小規模言語モデルを使用するタイミング
小規模言語モデルは、分析タスクが頻繁に繰り返され、予測可能なパターンに従う場合に最も効果を発揮します。これらのワークロードは、速度、効率、および安定したインフラストラクチャの動作を優先します。
一般的なSLMのユースケースには、次のようなものがあります。
-
ダッシュボードでのKPIの変化を説明する
-
チャートのインサイトを要約して、迅速なレビューを行う
-
反復的な分析的な質問に答える
-
メトリックの簡単な説明を生成する
-
内部の分析ワークフローをサポートする
これらのシナリオには、構造化されたデータと反復的なインタラクションが含まれます。より小さなモデルは迅速に応答し、より少ない計算リソースを必要とします。多くの分析ワークロードでは、この効率によりパフォーマンスが向上し、トークンの使用量とインフラストラクチャコストが予測可能に保たれます。
規制された環境で分析をデプロイする組織は、より小さなモデルを好む傾向があります。ローカルでモデルを実行することで、厳格なガバナンスとデータ保護の要件がサポートされます。これらのデプロイメントは、多くの場合、データが外部のモデルAPIに送信できない、セキュアな環境またはエアギャップ分析に存在します。 オンプレミス分析 またはエアギャップ分析で、データを外部のモデルAPIに送信することは許可されていません。

大規模言語モデルが理にかなる場合
大規模言語モデルは、質問に深い推論またはより広範なコンテキストが必要な場合に最も効果を発揮します。これらのシナリオには、単純なメトリックの説明を超えた、より複雑な分析的なタスクが含まれます。
一般的なLLMのユースケースには、次のようなものがあります。
-
多段階の分析的な質問を調査する
-
複雑なデータ関係を説明する
-
データセットからナラティブレポートを生成する
-
あいまいなユーザーのリクエストを解釈する
-
戦略的なデータ探索をサポートする
これらのリクエストには、より強力な推論と言語機能が必要です。LLMは、より大きなコンテキストを分析し、より詳細な応答を生成します。
分析タスクは複雑さに異なり、 SLMとLLM は、高速でコスト効率の高い応答と、より深く柔軟な推論とのバランスを反映しています。
AI分析のためのハイブリッドモデル戦略
ほとんどのAIを活用した埋め込み型分析システムは、 SLMとLLM を、選択肢として扱いません。両方を使用します。さまざまなタスクには、単純なメトリックの説明から、より深い分析的な解釈まで、異なるレベルの推論と速度が必要です。
ハイブリッドシステムは、リクエストを、タスクに最適なモデルにルーティングします。構造化された質問とダッシュボードの要約は、通常、より小さなモデルに送信されます。より複雑な分析的な質問は、より強力な推論機能を備えた、より大きなモデルをトリガーできます。この分離により、チームはパフォーマンスを制御しながら、高度な分析機能を維持できます。
分析システムにおける典型的なハイブリッドワークフローは次のとおりです。
-
分析エンジンは、接続された データソースに対してのみ
-
から構造化されたデータを取得します。
-
小規模言語モデルは、メトリックを要約するか、チャートの結果を説明します。
-
システムは、より深い推論を必要とする複雑な質問を検出します。
より大きなモデルは、高度なインサイトまたはナラティブな説明を生成します。
このアーキテクチャは、パフォーマンスとインテリジェンスのバランスをとります。より小さなモデルは、ダッシュボードとレポート全体で頻繁な運用タスクを処理します。より大きなモデルは、より広範な推論が必要な分析的な質問に焦点を当て、その場合、より高いトークンコストが許容されます。
ほとんどの組織にとって、ハイブリッドシステムは最も実用的な進むべき道を提供します。これにより、チームはAIを活用した分析をスケーリングしながら、分析レイヤー全体のレイテンシー、インフラストラクチャコスト、およびガバナンスを制御できます。
Revealがコスト管理されたAI分析をどのように実現するか
これらのアーキテクチャ上の課題が、分析プラットフォームが、単にAIモデルを統合するだけでなく、最初からパフォーマンス、コスト制御、およびガバナンスを設計する必要がある理由です。
そこで、 Reveal は、アーキテクチャに重点を置いてAIを構築します。Revealは、AIを分析レイヤーに直接埋め込み、チームがガバナンスまたはセキュリティの境界線を壊すことなく、会話型のインタラクションを導入できるようにします。製品チームは、インフラストラクチャを制御しながら、インテリジェントな分析機能を導入できます。

Revealは、次のアーキテクチャ機能を通じて、このアプローチをサポートします。
-
モデルの柔軟性 – SLMとLLMの両方を含む、ワークロードに最適なモデルを接続します。
-
トークンとコストの制御 – 予測可能なAIインフラストラクチャコストを維持するために、クエリの動作を管理します。
-
セキュアなデプロイ – 機密データを保護するために、分析とAIを環境内で実行します。
-
ロールベースのガバナンス – ダッシュボードと分析クエリ全体で、既存のアクセス許可モデルを尊重します。
-
埋め込み型分析アーキテクチャ – AIを製品エクスペリエンスに直接統合し、外部のチャットボットを追加するのではなく、
これらの機能により、チームは、インテリジェンス、効率、およびガバナンスのバランスをとる分析システムを構築できます。組織がSLMとLLMの戦略を評価し続けるにつれて、モデルの柔軟性とコスト制御を提供するアーキテクチャが、AIを活用した分析の次世代を定義します。
AIが埋め込み型分析の重要な部分になると、AIを使用するかどうかではなく、責任を持ってアーキテクチャを設計する方法が問題になります。成功するチームは、単に機能だけではなく、インテリジェンス、パフォーマンス、およびコストのバランスをとるチームになります。