
Scriptly Helps Pharmacies Identify Trends in Real Time with Reveal
Explore the complete guide to embedded analytics, including architecture, security, AI capabilities, implementation patterns, and evaluation criteria for modern applications.
Read NowFully branded white label dashboards offer custom personalization so that your customers can present a holistic service that is all branded to one company.
Read NowReveal business intelligence blog gives you the latest embedded analytics trends, how-tos, best practices, and product news.
The SLM vs. LLM choice affects latency, token costs, governance, and deployment flexibility. See which one fits your embedded analytics needs
Continue reading...
AI token cost is now a line item in the CIO’s budget, especially for SaaS teams shipping AI-powered embedded analytics. Every natural language query, generated dashboard, and automated insight inside your embedded analytics layer burns tokens from large language models. Across a multi-tenant SaaS platform with thousands of users, that adds up fast. Controlling AI token consumption requires real governance: guardrails, model flexibility, and usage monitoring. Reveal built these controls into its AI-powered embedded analytics from day one, so your team can scale AI analytics without watching costs spiral.
Continue reading...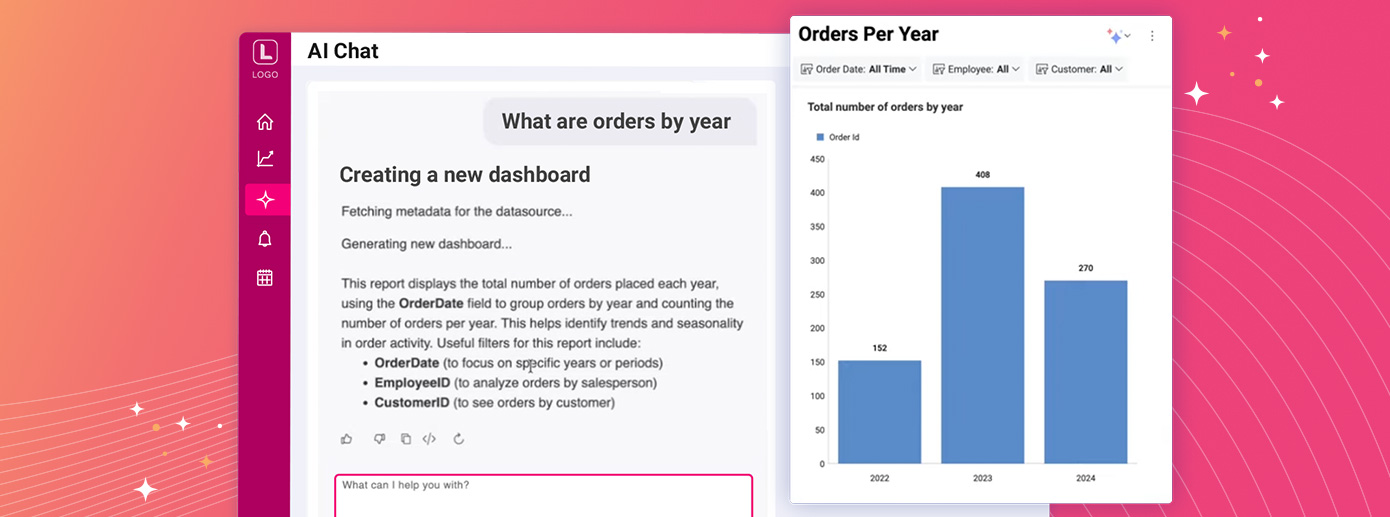
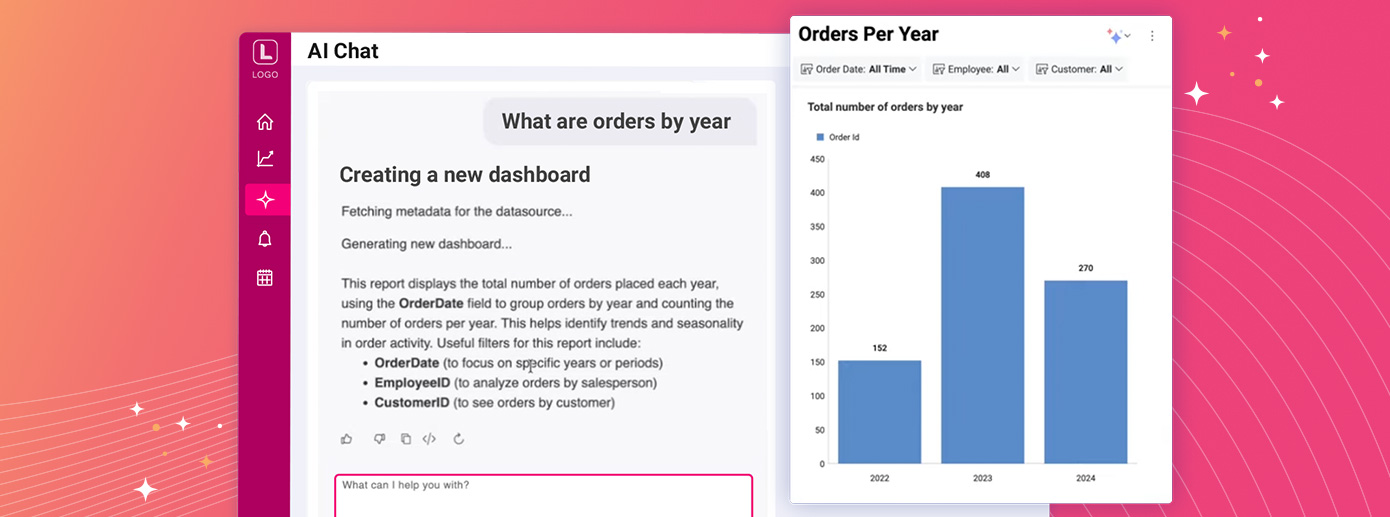
Learn how users can create AI-generated dashboards by asking natural-language questions right inside your product. A step-by-step guide
Continue reading...
How AI-powered analytics accelerates data insights and why Reveal offers secure, customer-controlled embedded AI analytics for modern apps.
Continue reading...
Learn how to ensure security with embedded analytics before implementing AI-powered analytics from a third-party provider.
Continue reading...
Learn how AI turns natural language into insights and how conversational analytics boost Saas and ISV products adoption and monetization
Continue reading...
