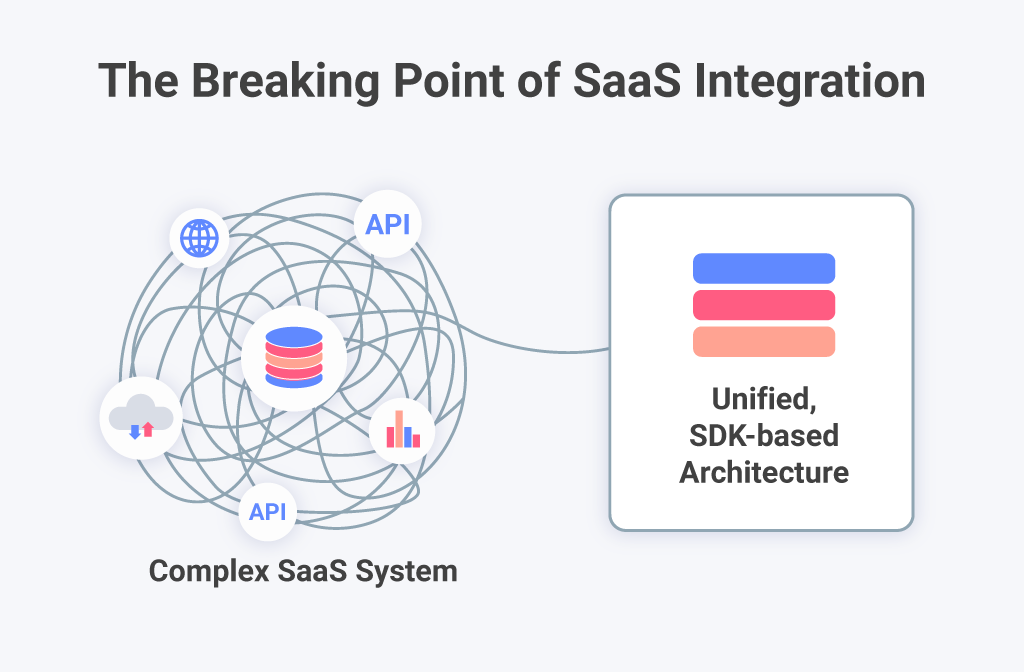
Toda arquitectura SaaS tiene un punto de quiebre. Para la mayoría de los ISV y productos SaaS, ese punto a menudo aparece con la integración de analítica.
Un nuevo panel o conector de datos parece simple, pero cada adición crea fricción oculta. Pronto, el rendimiento del producto sufre y los plazos comienzan a retrasarse.
Estos desafíos de integración de datos rara vez comienzan con los datos. Comienzan entre capas: APIs incompatibles, esquemas rígidos y herramientas que no fueron diseñadas para el despliegue continuo.
Los equipos pasan más tiempo arreglando problemas de integración de datos que mejorando la experiencia del usuario.
Para muchos CTO, la pregunta no es si fallará la analítica, sino cuándo. Cuanto más profundizan en pipelines personalizados, más frágil se vuelve el sistema.
Sin embargo, la analítica integrada no es opcional. No se puede simplemente decidir abandonar la capa de analítica de su producto. Después de todo, en 2025, 81% de los usuarios de análisis de datos utilizan analítica integrada. Esto convierte superar los desafíos de integración de datos en una cuestión de supervivencia, no de elección de característica. Por lo tanto, la pregunta no es si añadir analítica, sino cómo hacerlo sin construir una bomba de tiempo.
Ya cubrimos el contexto más amplio en nuestro artículo top challenges for embedded analytics. En este artículo, nos centraremos en el costo de la mala integración, cómo evitar pagar más por menos y cómo se ve una arquitectura escalable en la práctica.
El primer paso es entender qué causa los desafíos de integración.
Por Qué la Integración Falla en Entornos SaaS
La mayoría de los problemas de integración comienzan pequeños, pero crecen rápidamente. Las arquitecturas que funcionaron durante los lanzamientos iniciales a menudo tienen dificultades una vez que aumenta el volumen de datos y la actividad del usuario. Estos desafíos de integración de datos surgen cuando los equipos añaden nuevas APIs, fuentes de datos y herramientas de analítica sin una estructura compartida o un modelo de gobernanza. Las soluciones rápidas pueden resolver un problema a corto plazo, pero se acumulan en deuda técnica a largo plazo. Lo que comienza como una tarea de ingeniería pronto se convierte en un problema de UX y adopción.
Esquemas de Datos Dispares y Fuentes Fragmentadas
Cada producto SaaS depende de datos de múltiples sistemas, incluidas plataformas de facturación, CRMs, bases de datos en la nube y servicios internos. Cada una de estas fuentes utiliza un esquema y un ciclo de actualización únicos. Con el tiempo, la deriva del esquema crea inconsistencias entre paneles e informes. Estos problemas de integración de datos aparecen como KPI faltantes, métricas retrasadas o paneles que muestran resultados contradictorios. Para los usuarios, estos errores parecen analítica rota en lugar de incompatibilidades de backend. Una vez que se erosiona la confianza en la precisión de los datos, restaurarla requiere mucho más esfuerzo que mantenerla en primer lugar.
Herramientas BI Heredadas en un Stack SaaS Moderno
Muchos equipos intentan resolver la integración de analítica conectando plataformas BI heredadas que nunca fueron diseñadas para la entrega SaaS moderna. Estos sistemas dependen de servidores externos, modelos de datos rígidos y tasas de actualización lentas. Integrarlos introduce fricción en todos los niveles: el despliegue se ralentiza, los ciclos de actualización de datos se retrasan y las interfaces ya no se alinean con el producto. Estos desafíos de integración de sistemas obligan a los desarrolladores a comprometer entre velocidad y estabilidad. Para los usuarios, la analítica se siente como una herramienta externa, no como una característica nativa, y la adopción disminuye a medida que la experiencia pierde cohesión.
Fragilidad de la API y Deuda de Versionado
Los ciclos de desarrollo rápidos ejercen presión sobre las APIs para que evolucionen más rápido que los sistemas que dependen de ellas. Cada actualización de versión introduce nuevas dependencias y rompe los conectores existentes. Los desarrolladores parchean problemas con middleware, pero cada parche añade latencia y sobrecarga de mantenimiento. 47% de los líderes de ventas y RevOps enumeran la integración de datos en varios sistemas como su principal desafío de calidad de datos. Estos problemas recurrentes de integración de software no solo ralentizan a los ingenieros. Interrumpen la coherencia de la entrega de analítica, haciendo que las actualizaciones sean impredecibles y costosas.
El Efecto Dominó en UX y Confianza del Producto
Todos estos problemas (deriva del esquema, herramientas BI obsoletas y APIs frágiles) finalmente aparecen en la interfaz de usuario. Los paneles cargan lentamente, los filtros fallan y las visualizaciones dejan de reflejar datos en tiempo real. Cada pequeño fallo añade fricción a la experiencia y erosiona la credibilidad del producto. Con el tiempo, estos desafíos de integración recurrentes cambian la percepción: la analítica se siente poco fiable y los usuarios pierden confianza no solo en los conocimientos, sino en todo el producto. Para los líderes SaaS, el resultado es claro. La mala integración conduce a una mala adopción.
Los datos fragmentados, la infraestructura heredada y las APIs frágiles crean desafíos de integración de datos que drenan el tiempo de ingeniería y socavan la confianza del usuario. Arreglarlos después del lanzamiento cuesta más que abordarlos en el diseño. Saber dónde falla la integración es solo la mitad de la ecuación; el costo real aparece cuando esos fallos llegan a sus usuarios.
El Precio Oculto de la Analítica Mal Integrada
Los fallos de integración no se detienen en ingeniería. Se derraman en los cronogramas de entrega, la experiencia del cliente y la escalabilidad a largo plazo. Cuando falla la integración de analítica, drena silenciosamente recursos en todas las partes de un negocio SaaS. Estos desafíos de integración de datos se multiplican a medida que crecen los equipos, se expanden las herramientas y los usuarios esperan un acceso más rápido a la información. Lo que comienza como un retraso técnico pronto se convierte en una carga operativa y financiera.
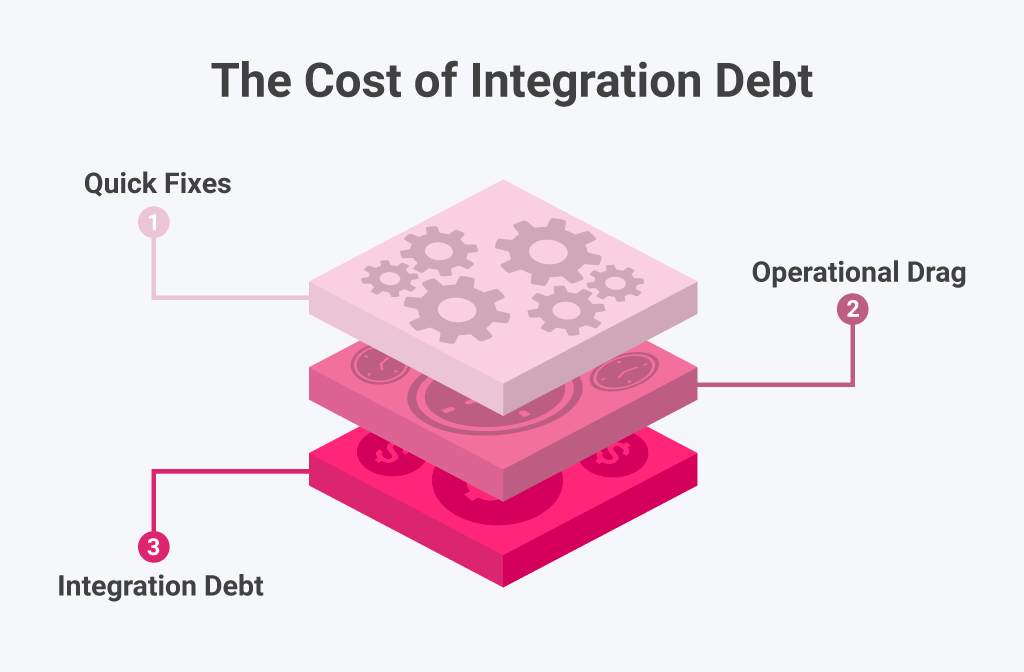
Deuda de Desarrollo y Pérdida de Velocidad
La analítica mal integrada conduce a retrabajos repetitivos, erosionando la velocidad de desarrollo. Cada cambio de API o deriva del esquema conduce a la depuración, las pruebas y la revalidación. Los equipos pierden el enfoque y el progreso se ralentiza. Con el tiempo, este desperdicio se traduce en pérdida de ingresos. Según Gartner, las empresas pierden un promedio de $15 millones de dólares por año debido a la mala calidad de los datos. El problema no es solo la ineficiencia técnica, sino la pérdida financiera directa. Cada fallo de integración aumenta el riesgo de retrasos en los lanzamientos y el mantenimiento no planificado, reduciendo el tiempo disponible para la innovación.
Arrastre Operacional y Sobrecarga de Mantenimiento
La ineficiencia operativa es uno de los resultados más costosos de la analítica fragmentada. Cuando los equipos hacen malabares con múltiples herramientas BI y pipelines, su productividad sufre. 61 percent de las organizaciones todavía utilizan cuatro o más plataformas de inteligencia de negocios, lo que obliga a los equipos a cambiar de contexto y perder hasta un 40 por ciento de su productividad. Al mismo tiempo, la mala calidad de los datos drena recursos, costando a las empresas más de 30 percent of their annual revenue. El resultado es predecible: mayores costos de mantenimiento, ejecución más lenta y menor agilidad.
Fragmentación de UX y Pérdida de Adopción
Los usuarios sienten los costos ocultos de la mala integración primero. Los paneles incompletos, los filtros rotos y los tiempos de carga lentos dañan la confianza y alejan a los clientes de la analítica del producto. Cuando los usuarios pierden confianza en sus datos, dejan de usar la función por completo. La mala calidad de los datos por sí sola cuesta a las empresas un promedio de $12.9 million per year. El impacto no termina ahí. El 57 por ciento de los usuarios activos semanales nunca interactúan con funciones que impulsan más del 70 por ciento de los ingresos por expansión, lo que resulta en $27,960 in lost revenue per account durante tres años. Una fuerte integración previene directamente esta deuda de adopción. Como se describe en Boost Customer Retention with Embedded Analytics, la analítica fiable impulsa el compromiso, la retención y la expansión.
El Efecto Compuesto en la Escala y el Crecimiento
Los costos de integración crecen con cada nuevo cliente, característica o fuente de datos. Arreglar problemas después del lanzamiento requiere más esfuerzo que diseñarlos al principio. Cada solución temporal añade latencia, introduce dependencias y multiplica las horas de mantenimiento. Cuando los equipos notan el impacto total, los desafíos de integración ya han reducido la velocidad e inflado los costos de soporte. A medida que la base de clientes escala, esas ineficiencias también lo hacen.
La mala integración de analítica cuesta mucho más que unos pocos sprints retrasados. Drena el tiempo de desarrollo, infla los costos operativos hasta en $3 millones durante 10 años y daña la confianza del usuario. El siguiente paso no es parchear lo que está roto, sino prevenir que se forme nueva deuda. Evitar estos costos significa pensar en el diseño de la integración desde el principio, no en repararla después del lanzamiento.
Evitando la Deuda de Integración
Arreglar problemas de integración después del lanzamiento siempre cuesta más que prevenirlos en el diseño. Cada solución temporal rápida añade complejidad oculta, y esas soluciones a corto plazo se acumulan con el tiempo. La deuda de integración ocurre cuando los equipos siguen parcheando problemas de integración de datos en lugar de abordar sus causas raíz. Cuanto más tiempo se ignora, más difícil es escalar.
Planificación Arquitectónica Antes de Escalar
Las decisiones heredadas son la mayor fuente de problemas futuros. 32% de los usuarios de analítica citan la infraestructura heredada como la principal barrera para la adopción. Muchos equipos escalan antes de estandarizar sus modelos de datos o su estrategia de versionado de API, dejándolos persiguiendo la compatibilidad más tarde. Una planificación arquitectónica clara, con esquemas compartidos, APIs unificadas y gobernanza bien definida, previene los desafíos de integración de sistemas antes de que ocurran. Construir sobre marcos y SDKs flexibles da a los equipos la capacidad de adaptarse a medida que evolucionan las fuentes de datos y las demandas de los clientes.
Alineando Decisiones de Producto e Ingeniería
La deuda de integración a menudo crece en la brecha entre la urgencia del producto y la disciplina de ingeniería. Los equipos de producto presionan por lanzamientos más rápidos, mientras que los desarrolladores luchan por mantener la estabilidad. Cuando los plazos ganan, la documentación, las pruebas y la automatización pierden. Con el tiempo, estas pequeñas omisiones se acumulan en graves problemas de integración de datos que ralentizan cada lanzamiento subsiguiente. Prevenir esto requiere alineación entre los equipos. Producto e ingeniería deben compartir la propiedad de la calidad de la integración, tratando el flujo de datos como parte de la experiencia central del producto, no como un proceso de fondo.
Evaluación de Decisiones de Construir vs. Comprar
En algún momento, cada equipo se enfrenta a una elección estratégica: construir integraciones internamente o incrustar un SDK existente. Ambos tienen compensaciones. Construir da control, pero requiere mantenimiento a largo plazo y experiencia más profunda. Comprar acelera la entrega, pero puede introducir dependencias si no se elige con cuidado. La clave es la claridad sobre qué opción se alinea con la escala, la flexibilidad y la capacidad del equipo. La decisión de build vs. buy analytics no se trata solo de velocidad. Se trata de establecer una arquitectura que pueda crecer sin ser reescrita cada año.
Diseño de Integración a Prueba de Futuro
La integración nunca está terminada. Las APIs evolucionan, los pipelines de datos se expanden y los nuevos frameworks reemplazan a los viejos. Los equipos que planifican el cambio evitan quedar atrapados en una configuración frágil. Las APIs modulares, las capas de observabilidad y la integración SDK-first reducen los problemas de integración de software a largo plazo, haciendo que la iteración sea predecible. La flexibilidad técnica crea estabilidad del producto. Para una vista detallada de cómo se ve la preparación, consulte Embedded Analytics Requirements for 2025.
La planificación proactiva convierte la integración de una carga de mantenimiento en un habilitador de crecimiento. Cada hora dedicada a alinear la arquitectura temprano ahorra semanas de depuración más tarde. Los equipos que planifican la escala no solo evitan la deuda de integración. Construyen una base lista para una integración más inteligente y rápida.
Analítica Integrada: La Manera Más Inteligente de Integrar
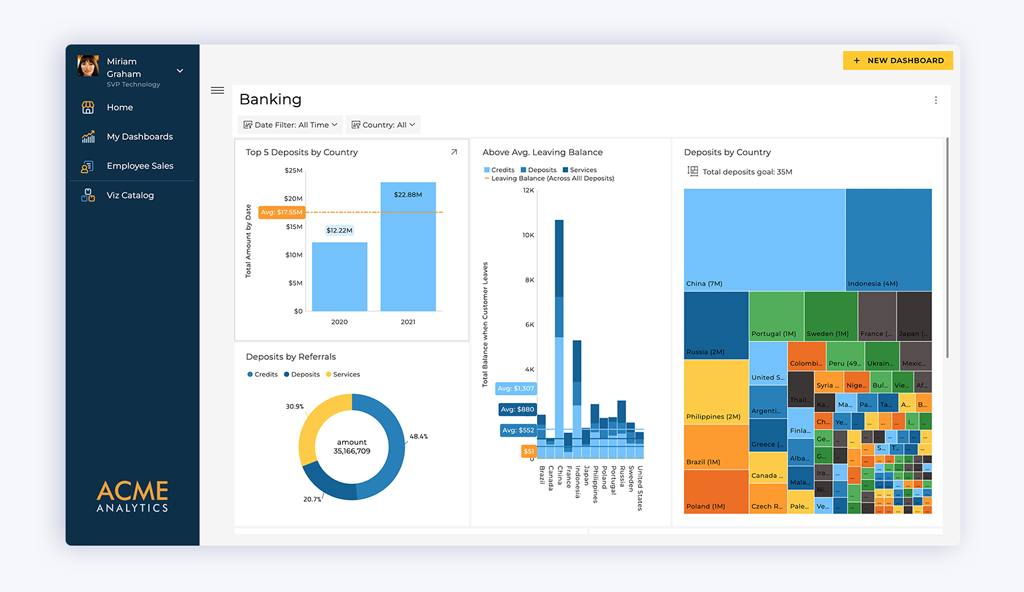
Evitar la deuda de integración es una cosa; reemplazar la complejidad con simplicidad es otra. Los equipos SaaS que dependen de configuraciones BI tradicionales continúan enfrentando los mismos desafíos de integración de datos año tras año. Cada nueva fuente de datos o panel aumenta el mantenimiento y ralentiza el desarrollo. Un enfoque más inteligente reemplaza múltiples conectores y sistemas de terceros con una única arquitectura integrada que mantiene los datos, la lógica y la experiencia en un solo lugar.
Unificando Datos y Experiencia
Embedded analytics cambia la forma en que los equipos piensan sobre los datos. En lugar de conectar herramientas BI externas, la lógica de analítica vive directamente dentro del producto a través de la integración SDK-first. Esto elimina las capas de APIs y conectores personalizados que normalmente se encuentran entre los datos y la interfaz. Al integrar la analítica de forma nativa, los equipos eliminan pipelines redundantes y reducen los desafíos de integración que provienen de la sincronización de múltiples sistemas. Los datos se mueven a través de un flujo controlado, dando a los usuarios información más rápida y a los desarrolladores menos piezas móviles que gestionar.
Rendimiento en Tiempo Real y Escalabilidad
Las integraciones tradicionales dependen del almacenamiento en caché y de trabajos de sincronización que rápidamente se convierten en cuellos de botella. La analítica integrada se ejecuta dentro de la misma capa de aplicación que el producto central, lo que permite consultas de datos en tiempo real. Esto reduce la latencia y mejora la capacidad de respuesta para cada interacción con el panel. Al consolidar el acceso a los datos, los equipos minimizan los desafíos de integración de sistemas causados por la deriva de versiones y las incompatibilidades de API. La arquitectura escala de manera predecible porque no hay dependencia externa entre la analítica y el producto en sí.
Consistencia de UX y Adopción
Cuando la analítica se siente desconectada, la adopción cae. La analítica integrada resuelve esto mezclando la visualización, la interacción y la marca dentro del mismo marco de UX. Los usuarios permanecen en contexto, evitando la necesidad de cambiar entre herramientas o pantallas. Dado que las capas de UI y datos operan juntas, los problemas comunes de integración de software, como filtros rotos, estilos inconsistentes y ciclos de actualización incompatibles, desaparecen. El resultado es una analítica que se siente diseñada para el producto, no añadida a él. Esa consistencia impulsa tanto la adopción como la confianza.
IA y la Próxima Fase de Analítica Integrada
La analítica está evolucionando rápido. Para 2026, más del 80% de los proveedores de software tendrán capacidades GenAI integradas en sus productos. AI-powered analytics convierte los paneles en motores de decisiones que muestran conocimientos automáticamente. Cuando se combina con el diseño integrado, la IA pasa de una capa de informes separada a una característica proactiva dentro del producto. Este cambio convierte la analítica de informes reactivos a una experiencia de inteligencia continua que escala con cada usuario.
La analítica integrada reemplaza la complejidad con cohesión. Resuelve los problemas de integración de datos antes de que comiencen al fusionar la analítica en el flujo de trabajo natural del producto. Para las empresas SaaS que buscan modernizar su enfoque, esto no es solo una actualización. Es un cambio arquitectónico. Para ejemplos de cómo los líderes aplican este modelo, consulte Embedded Analytics for SaaS Companies. Los principios detrás de la analítica integrada son poderosos por sí mismos. A continuación, veremos cómo funcionan en la práctica.
Cómo Reveal Simplifica la Integración a Escala
Reveal lleva a la práctica todo lo discutido en este artículo. Está construido para resolver los desafíos de integración que hacen que la analítica sea lenta, costosa e inconsistente. Al centrarse en la integración SDK-first, la conectividad unificada y la UX perfecta, Reveal ayuda a los equipos SaaS a reemplazar la complejidad con control.
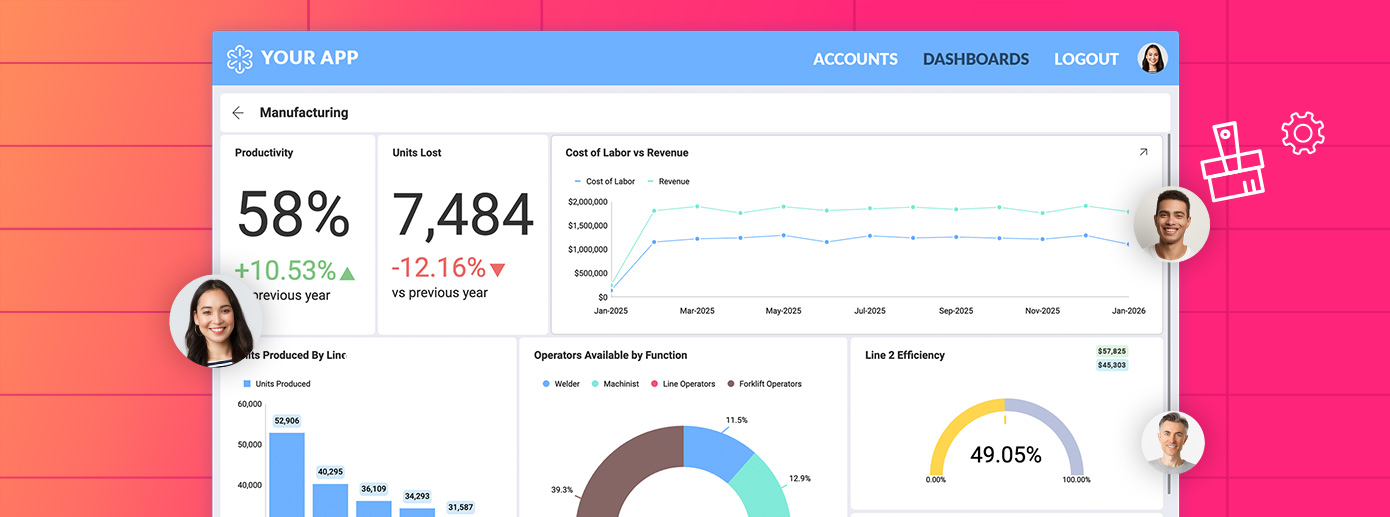
Reveal no es otra capa de analítica. Es una arquitectura diseñada para equipos que necesitan que la analítica funcione de forma nativa dentro de su producto, no a su lado. Cada capacidad aborda un punto de dolor específico causado por sistemas fragmentados y deuda técnica:
-
Arquitectura SDK-first – Incrusta la analítica directamente en la base de código, eliminando conectores redundantes y reduciendo problemas de integración de datos antes de que lleguen a producción.
-
Conectividad Unificada – Accede a múltiples data sources a través de una capa segura que escala en entornos SQL, REST y en la nube.
-
Analítica Fullwhite-label analytics – Entrega paneles que coinciden con la marca y la UX de su producto, asegurando que la analítica se sienta como parte de la experiencia.
-
Escalabilidad Predecible – Maneja el creciente volumen de datos y múltiples inquilinos sin caídas de rendimiento ni complejidad de costos añadida.
-
Probado en la Práctica – La Atanasoft story demuestra cómo un equipo SaaS unificó múltiples sistemas y redujo el tiempo de desarrollo en un 60% al utilizar el modelo de integración SDK-first de Reveal.
Reveal está construido para equipos que ven la integración como una estrategia de crecimiento, no como una tarea de mantenimiento. Les ayuda a superar los desafíos de integración de datos y a construir experiencias de analítica que escalan tan naturalmente como su producto. La integración debe acelerar el valor del producto, no ralentizarlo, y Reveal hace posible eso.
Analítica Personalizada para Usted
Tome el control completo de su representación de datos con Reveal.