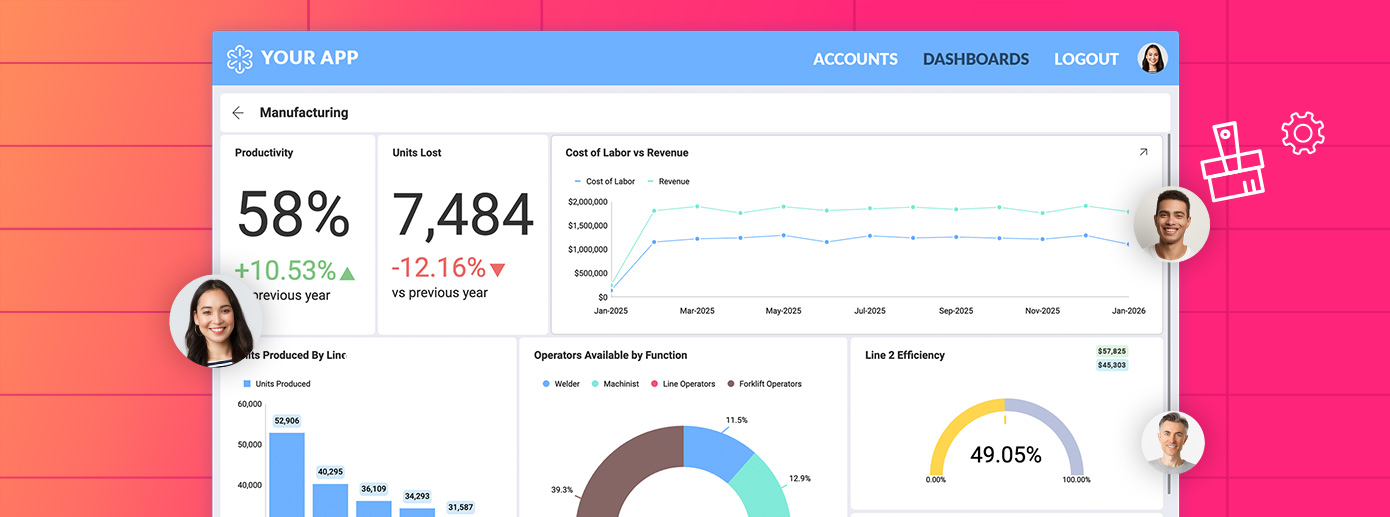
Scriptly Helps Pharmacies Identify Trends in Real Time with Reveal
Explore the complete guide to embedded analytics, including architecture, security, AI capabilities, implementation patterns, and evaluation criteria for modern applications.
Read NowFully branded white label dashboards offer custom personalization so that your customers can present a holistic service that is all branded to one company.
Read Nowデータ統合の課題はコストを増加させ、SaaSの成長を遅らせます。組み込み分析が、いかに迅速でシンプルなスケーリングを実現するかを発見してください。
Executive Summary:
Key Takeaways:
すべてのSaaSアーキテクチャには、限界点があります。ほとんどのISVおよびSaaS製品にとって、その点はしばしば分析機能の統合に伴って現れます。
新しいダッシュボードやデータコネクタはシンプルに見えますが、追加されるたびに隠れた摩擦が生じます。やがて製品のパフォーマンスが低下し、納期が遅れ始めます。
これらのデータ統合の課題は、めったにデータから始まらないのです。それはレイヤーの間、つまりミスマッチなAPI、硬直したスキーマ、そして継続的なデプロイメントのために設計されていないツールから始まります。
チームは、ユーザーエクスペリエンスの改善よりも、データ統合の問題を修正することに多くの時間を費やします。
多くのCTOにとって、問題は分析が失敗するかどうかではなく、いつ失敗するかということです。カスタムパイプラインに深く入り込むほど、システムは脆くなります。
しかし、統合分析はオプションではありません。製品の分析レイヤーを単に放棄すると決めるわけにはいきません。結局のところ、2025年には、81%のデータ分析ユーザーが組み込み分析を利用しているからです。これは、データ統合の課題を克服することが、機能の選択ではなく、生き残りの問題であることを意味します。したがって、問題は分析を追加するかどうかではなく、時限爆弾を構築せずにどのように行うかということです。
より広範な背景については、組み込み分析のためのトップ課題の記事で取り上げました。この記事では、不十分な統合のコスト、より少ないものに対してより多くのお金を払うのを避ける方法、そして実務におけるスケーラブルなアーキテクチャがどのようなものかという点に焦点を当てます。
最初の手順は、何が統合の課題を引き起こすのかを理解することです。
ほとんどの統合の問題は小さく始まりますが、急速に拡大します。初期リリース時には機能したアーキテクチャも、データ量とユーザーアクティビティが増加すると苦労することがよくあります。これらのデータ統合の課題は、チームが共有の構造やガバナンスモデルなしに、新しいAPI、データソース、分析ツールを追加するときに発生します。一時的な修正は短期的な問題を解決するかもしれませんが、それは長期的な技術的負債として積み重なります。エンジニアリングのタスクとして始まったものが、すぐにUXおよび導入の問題になります。
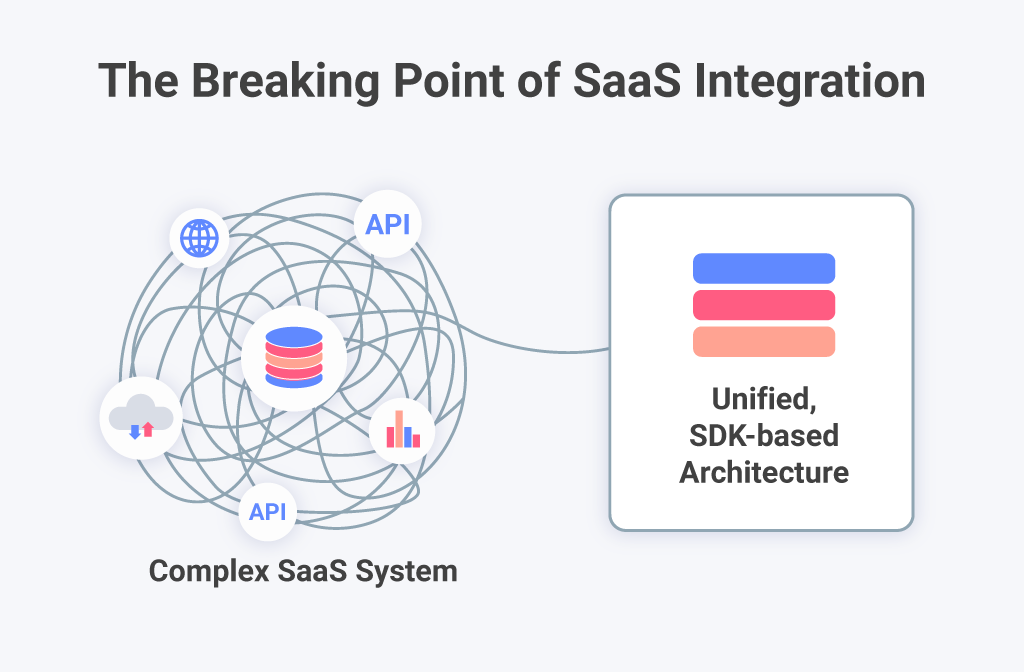
すべてのSaaS製品は、請求プラットフォーム、CRM、クラウドデータベース、内部サービスなど、複数のシステムからのデータに依存しています。これらの各ソースは、固有のスキーマと更新サイクルを使用しています。時間の経過とともに、スキーマドリフトはダッシュボードとレポートの間で不整合を引き起こします。これらのデータ統合の問題は、KPIの欠落、メトリクスの遅延、または矛盾した結果を示すダッシュボードとして表面化します。ユーザーにとって、これらのエラーはバックエンドの不一致というよりも、壊れた分析のように見えます。データ精度への信頼が失われると、それを回復するには、最初から維持するよりもはるかに多くの労力が必要です。
多くのチームは、最新のSaaS提供に設計されていないレガシーなBIプラットフォームを接続することで、分析統合を解決しようとします。これらのシステムは、外部サーバー、硬直したデータモデル、そして遅い更新レートに依存しています。これらを組み込むことは、あらゆるレベルで摩擦を生じさせます。デプロイメントが遅くなり、データ更新サイクルが遅れ、インターフェースが製品と一致しなくなります。これらのシステム統合の課題は、開発者にスピードと安定性の間で妥協を強います。ユーザーにとって、分析はネイティブな機能ではなく外部ツールのように感じられ、体験の一貫性が失われるにつれて導入率が低下します。
急速な開発サイクルは、APIにそれらに依存するシステムよりも速く進化するよう圧力をかけます。各バージョンアップは新しい依存関係を導入し、既存のコネクタを壊します。開発者はミドルウェアで問題をパッチしますが、パッチを適用するたびにレイテンシとメンテナンスオーバーヘッドが増加します。47%のセールスおよびRevOpsリーダーは、システムを横断するデータ統合を最大のデータ品質の課題として挙げています。これらの繰り返されるソフトウェア統合の問題は、エンジニアを遅らせるだけではありません。分析提供の一貫性を乱し、アップデートを予測不可能でコストのかかるものにします。
これらのすべての問題(スキーマドリフト、古いBIツール、脆弱なAPI)は、最終的にユーザーインターフェースに表面化します。ダッシュボードの読み込みが遅くなり、フィルターが壊れ、ビジュアライゼーションがリアルタイムのデータを反映しなくなります。小さな失敗が積み重なるたびに、体験に摩擦が加わり、製品の信頼性が低下します。時間の経過とともに、これらの繰り返される統合の課題は認識を変えます。分析は信頼できないと感じられ、ユーザーはインサイトだけでなく、製品全体に対する信頼を失います。SaaSリーダーにとって、結果は明らかです。不十分な統合は、不十分な導入につながります。
断片化されたデータ、レガシーなインフラストラクチャ、そして脆いAPIは、エンジニアリングの時間を浪費し、ユーザーの信頼性を損なうデータ統合の課題を生み出します。リリース後に修正することは、設計段階で対処するよりもコストがかかります。どこで統合が破綻するかを知ることは方程式の半分に過ぎません。真のコストは、それらの失敗がユーザーに届いたときに現れるのです。
統合の失敗は、エンジニアリングに留まりません。デリバリースケジュール、顧客体験、長期的なスケーラビリティにまで波及します。分析統合が破綻すると、SaaSビジネスのあらゆる部分で静かにリソースが消耗します。これらのデータ統合の課題は、チームが成長し、ツールが拡大し、ユーザーがより迅速なインサイトを期待するにつれて倍増します。技術的な遅延として始まったものが、すぐに運用上および財政的な負担になります。
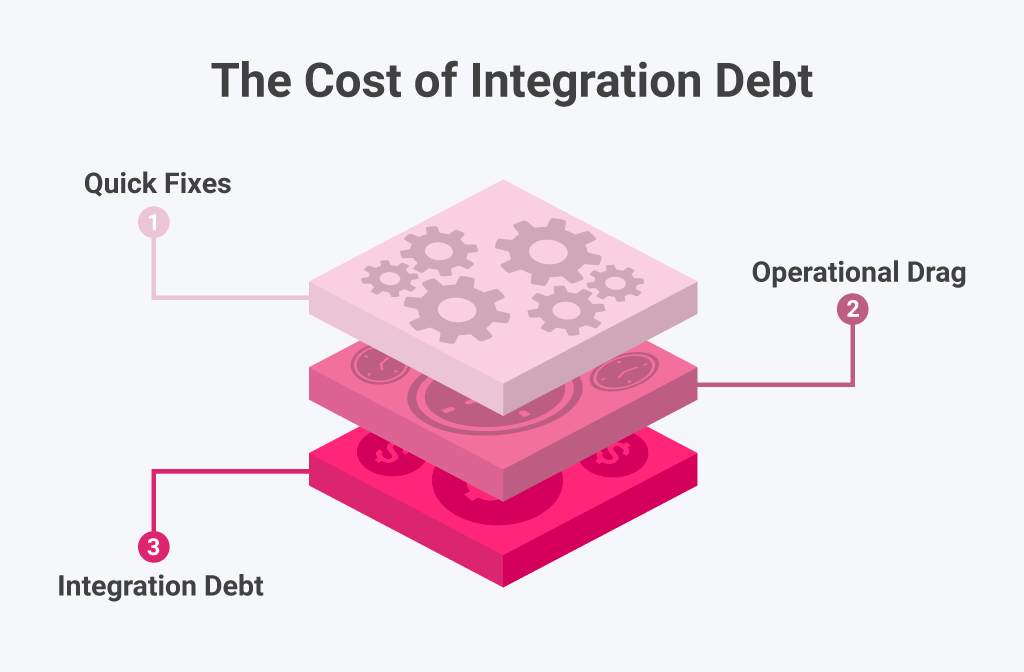
不十分な組み込み分析は、反復的な再作業を引き起こし、開発速度を低下させます。APIの変更やスキーマドリフトのたびに、デバッグ、再テスト、再検証が必要になります。チームは集中力を失い、進捗が遅くなります。時間の経過とともに、この無駄は失われた収益に変換されます。Gartnerによると、企業はデータ品質の低さによって平均して年間1,500万ドルを失っています。問題は単なる技術的な非効率性ではなく、直接的な金銭的損失です。すべての統合の欠陥は、リリース遅延や計画外のメンテナンスのリスクを高め、イノベーションのための利用可能な時間を減らします。
運用上の非効率性は、断片化された分析の最も高価な結果の一つです。チームが複数のBIツールとパイプラインを扱うとき、生産性が低下します。61 percentの組織が依然として4つ以上のビジネスインテリジェンスプラットフォームを使用しており、チームはコンテキストスイッチを強いられ、生産性の最大40パーセントを失っています。同時に、データ品質の低さはリソースを消耗させ、企業に年間売上の30パーセント以上のコストをかけています。結果は予測可能です。より高いメンテナンスコスト、より遅い実行、そして減衰したアジリティです。
ユーザーは、不十分な統合の隠れたコストを最初に感じます。不完全なダッシュボード、壊れたフィルター、遅い読み込み時間は信頼性を損ない、顧客を製品分析から遠ざけます。ユーザーがデータに対する自信を失うと、その機能を完全に使用しなくなります。データ品質の低さだけで、企業は平均して年間1,290万ドルのコストをかけています。影響はそれだけにとどまりません。週次のアクティブユーザーの57パーセントが、拡大収益の70パーセント以上を推進する機能には一度も関与せず、3年間でアカウントあたり27,960ドルの損失収益をもたらします。強力な統合は、この負債の導入を直接的に防ぎます。 Boost Customer Retention with Embedded Analyticsで概説されているように、信頼性の高い分析は、エンゲージメント、リテンション、そして拡大を推進します。
統合コストは、新しい顧客、機能、またはデータソースごとに増加します。リリース後に問題を修正することは、設計段階でそれらを予防するよりも多くの労力を必要とします。回避策を一つ追加するたびに、レイテンシが加わり、依存関係が導入され、メンテナンス時間が倍増します。チームが完全な影響に気づく頃には、統合の課題はすでに速度を低下させ、サポートコストを膨らませています。顧客ベースが拡大するにつれて、それらの非効率性も拡大します。
不十分な分析統合のコストは、単に遅れたスプリントの数倍ではありません。それは開発時間を消耗させ、運用コストを10年間で最大300万ドルまで膨らませ、ユーザーの信頼性を損ないます。次のステップは、壊れたものをパッチすることではなく、新しい負債の形成を防ぐことです。これらのコストを回避するということは、ローンチ後に修理することではなく、最初から統合設計について考えることを意味します。
ローンチ後に統合の問題を修正することは、設計段階で予防するよりも常にコストがかかります。すべての簡単な回避策は隠れた複雑さを加え、それらの短期的な修正は時間とともに蓄積します。統合負債とは、チームが根本原因に対処する代わりに、データ統合の問題をパッチし続ける状態を指します。無視する時間が長ければ長いほど、スケールすることが難しくなります。
レガシーな決定は、将来の問題の最大の発生源です。32%の分析ユーザーは、レガシーなインフラストラクチャを導入の主な障壁として挙げています。多くのチームは、データモデルやAPIのバージョン管理戦略を標準化する前にスケールし、後で互換性を追いかけることになります。共有スキーマ、統一API、そして明確に定義されたガバナンスを備えた明確なアーキテクチャ計画は、システム統合の課題が発生するのを防ぎます。柔軟なフレームワークやSDKの上に構築することは、データソースと顧客の要求が進化するにつれて、チームが適応する能力を与えます。
統合負債は、製品の緊急性とエンジニアリングの規律の間のギャップで成長することがよくあります。製品チームはより速いリリースを求め、開発者は安定性を維持するために戦います。納期が勝つとき、ドキュメント、テスト、自動化が失われます。時間の経過とともに、これらの小さな省略は深刻なデータ統合の問題に蓄積し、その後のすべてのリリースを遅らせます。これを防ぐには、チーム間の整合性が必要です。製品とエンジニアリングは、データフローをバックグラウンドプロセスではなく、コアな製品体験の一部として扱い、統合の品質について共同の責任を負わなければなりません。
いずれかの時点で、すべてのチームは戦略的な選択に直面します。統合を内部で構築するか、既存のSDKを組み込むかです。どちらにもトレードオフがあります。構築は制御を提供しますが、長期的なメンテナンスとより深い専門知識を必要とします。購入はデリバリーを加速させますが、注意深く選ばれない場合、依存関係を導入する可能性があります。鍵は、どのオプションがスケール、柔軟性、およびチームの能力に合致しているかについての明確さです。build vs. buy analyticsの決定は、単にスピードに関するものではありません。それは、毎年書き直されることなく成長できるアーキテクチャを構築することに関するものです。
統合は決して完了しません。APIは進化し、データパイプラインは拡大し、新しいフレームワークが古いものを置き換えます。変化に備えるチームは、脆いセットアップに閉じ込められることを避けます。モジュラーAPI、オブザーバビリティレイヤー、そしてSDKファーストの組み込みは、長期的なソフトウェア統合の問題を減らし、イテレーションを予測可能にします。技術的な柔軟性が製品の安定性を作り出します。準備がどのようなものかについての詳細なビューについては、Embedded Analytics Requirements for 2025.を参照してください。
プロアクティブな計画は、統合をメンテナンスの負担から成長の促進剤へと変えます。アーキテクチャを早期に整合させるために費やされたすべての時間は、後で何週間ものデバッグを節約します。スケールに備えるチームは、単に統合負債を避けるだけではありません。よりスマートで速い組み込みに備えた基盤を構築します。
統合負債を回避することは一つのことですが、複雑さをシンプルさに置き換えることは別のことです。従来のBIセットアップに依存するSaaSチームは、年々同じデータ統合の課題に直面し続けています。新しいデータソースやダッシュボードが追加されるたびに、メンテナンスが増加し、開発が遅くなります。よりスマートなアプローチは、複数のコネクタやサードパーティシステムを、データ、ロジック、体験を一つの場所に保つ単一の組み込みアーキテクチャに置き換えます。
組み込み分析は、チームがデータについて考える方法を変えます。外部のBIツールを接続する代わりに、分析ロジックはSDKファーストの組み込みを通じて製品の内部に直接存在します。これにより、通常、データとインターフェースの間に存在するAPIやカスタムコネクタのレイヤーが取り除かれます。分析をネイティブに統合することで、チームは冗長なパイプラインを排除し、複数のシステムを同期することから生じる統合の課題を減らします。データは単一の制御されたフローを通り、ユーザーにはより迅速なインサイトを、開発者には管理すべき部品を減らします。
従来の統合は、すぐにボトルネックとなるキャッシングと同期ジョブに依存しています。組み込み分析は、コア製品と同じアプリケーションレイヤー内で実行されるため、リアルタイムのデータクエリを可能にします。これによりレイテンシが減り、すべてのダッシュボード操作の応答性が向上します。データアクセスを統合することで、チームはバージョンドリフトやAPIのミスマッチによって引き起こされるシステム統合の課題を最小限に抑えます。アーキテクチャは、分析と製品自体との間に外部依存関係がないため、予測可能にスケールします。
分析が切り離されていると感じると、導入率は低下します。組み込み分析は、ビジュアライゼーション、インタラクション、ブランディングを同じUXフレームワーク内でブレンドすることでこれを解決します。ユーザーはコンテキスト内に留まり、ツールや画面を切り替える必要がなくなります。UIとデータレイヤーが一緒に動作するため、壊れたフィルター、一貫性のないスタイリング、ミスマッチな更新サイクルといった一般的なソフトウェア統合の問題が消滅します。その結果は、製品に追加されたように見えるのではなく、製品のために設計されたように感じられる分析です。この一貫性が、導入と信頼性の両方を推進します。
分析は急速に進化しています。2026年までに、ソフトウェアベンダーの80%以上が製品に組み込みGenAI機能を持つようになります。AIを活用した分析は、ダッシュボードを自動的にインサイトを表面化させる意思決定エンジンに変えます。組み込みデザインと組み合わせることで、AIは別のレポートレイヤーから、プロアクティブな製品内機能へと移行します。このシフトは、分析をリアクティブなレポートから、すべてのユーザーと共にスケールする継続的なインテリジェンス体験へと変えます。
組み込み分析は、複雑さを一貫性で置き換えます。分析を製品の自然なワークフローに統合することで、問題が発生する前にデータ統合の問題を解決します。アプローチを近代化しようとしているSaaS企業にとって、これは単なるアップグレードではありません。それはアーキテクチャの転換です。リーダーがこのモデルをどのように適用するかについての例については、Embedded Analytics for SaaS Companiesを参照してください。組み込み分析の背後にある原則はそれ自体で強力です。次に、それらが実務でどのように機能するかを見ていきましょう。
Revealは、この記事で議論されたすべてを実務に適用します。それは、分析を遅く、コストがかかり、一貫性がないものにする統合の課題を解決するために構築されています。SDKファーストの組み込み、統一された接続性、シームレスなUXに焦点を当てることで、RevealはSaaSチームが複雑さを制御に置き換えるのを支援します。
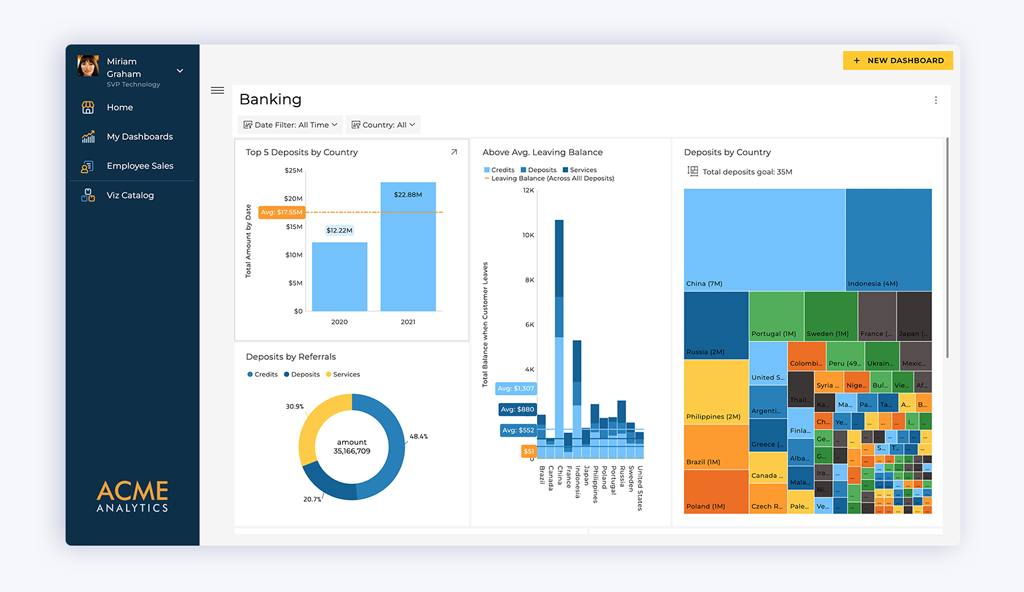
Revealは、別の分析レイヤーではありません。それは、分析を隣ではなく、製品の内部でネイティブに動作させる必要があるチームのために設計されたアーキテクチャです。各機能は、断片化されたシステムと技術的負債によって引き起こされる特定のペインポイントに対処しています。
SDKファーストアーキテクチャ – 分析をコードベースに直接組み込み、冗長なコネクタを排除し、データ統合の問題が本番環境に到達する前に削減します。
統一された接続性 – SQL、REST、およびクラウド環境にわたってスケールする単一のセキュアなレイヤーを通じて、複数のデータソースにアクセスできます。
完全なホワイトラベル分析 – ダッシュボードを、製品のブランディングとUXに一致するように提供し、分析が体験の一部であるように感じられることを保証します。
予測可能なスケーラビリティ – パフォーマンスの低下や追加のコスト複雑さなしに、増加するデータ量と複数のマルチテナントを処理します。
実証済みの実績 – Atanasoftの事例は、あるSaaSチームが複数のシステムを統合し、RevealのSDKファーストの統合モデルを利用することで開発時間を60%削減した方法を実証しています。
Revealは、統合をメンテナンスタスクではなく成長戦略と見なすチームのために構築されています。それは、データ統合の課題を乗り越え、製品と同じくらい自然にスケールする分析体験を構築するのを支援します。統合は製品価値を加速させるべきであり、遅らせるべきではありません。そして、Revealはそれが可能にします。
あなたに合わせた分析
Revealでデータ表現を完全にコントロールしましょう。